今天读了一篇文章,关于语言之间相互促进或抑制的问题,这个是训练大模型时候的问题。其实我觉得也可以推广用在人类的普通学习上,下面就是我的一些思考。
一、知识是相互促进或抑制的
不同语言之间共同训练会出现“正迁移”或“负干扰”,并且这种关系有明显结构。比如类型相近的语言,西班牙语、葡萄牙语加泰罗尼亚语他们是互相促进的,但是比如中文跟西班牙语就是相互抑制的。推广到人类的学习上也是同样的道理。不同的知识之间也是有促进或抑制作用的。比如你学了希腊历史,对英语、对世界历史、欧洲历史,都会有促进作用,甚至对化学都有促进作用。但是如果你不幸学了宋明理学、朱熹的儒学思想,你可能学任何西方的东西都会受到抑制。
人类学习中,“先学什么、和什么一起学”不是个人偏好问题,而是可预测的结构性迁移:相似领域/相近表征更可能互相增益;差异巨大时更容易互相打架。有些知识天然的就会抑制其他的知识。这种知识学了还不如不学。
相似领域共享更多“中间表征”,包括词形/语法/符号系统、概念分类、逻辑和推理过程等等。共享越多,新的输入越容易落到已有结构上;反之会在相同的注意力与记忆资源上竞争,产生混淆与遗忘。
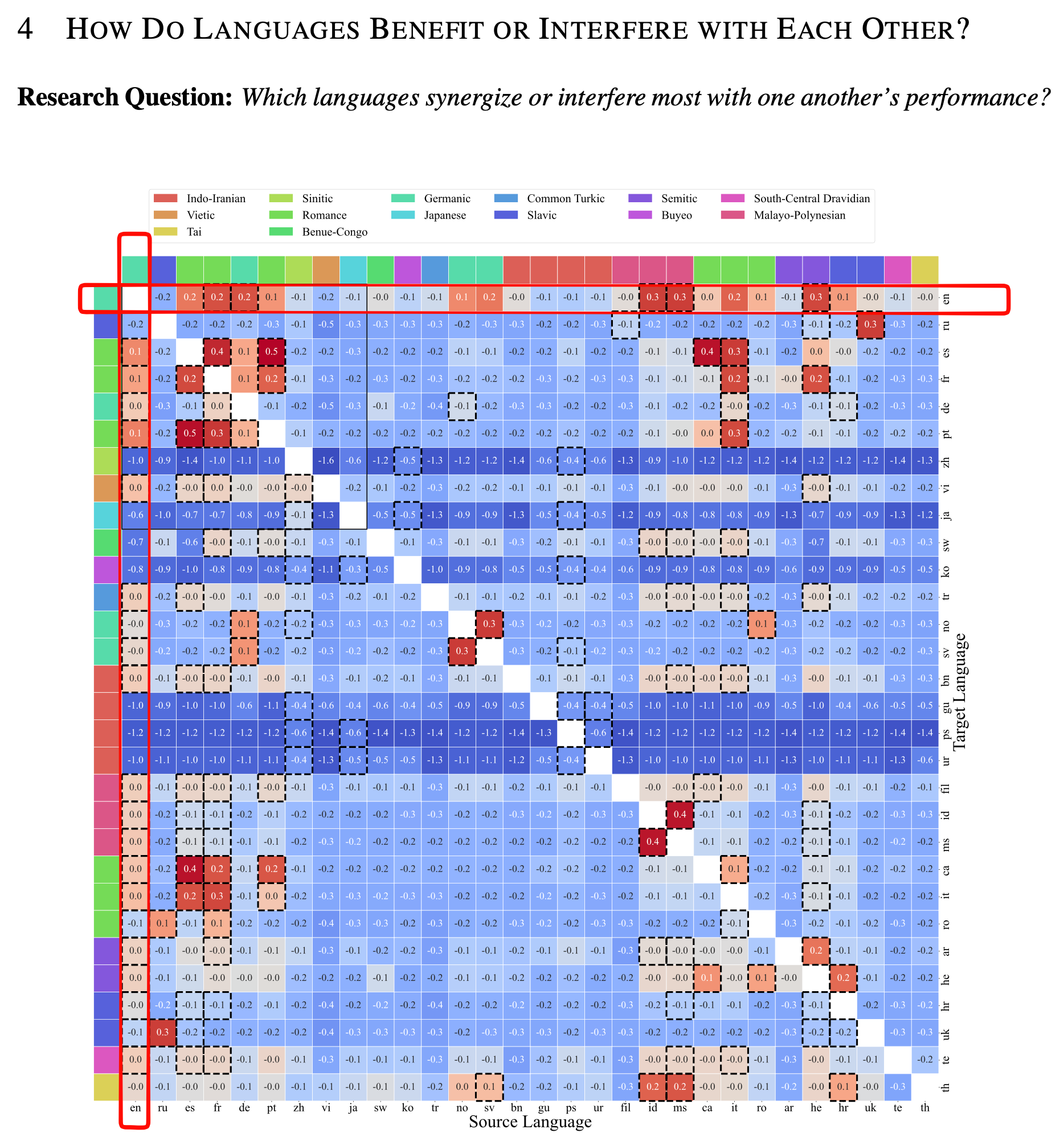
英语为什么重要? 这个图,是训练大模型时,各个语言的相互影响。红的是促进,蓝的是拖后腿。 可以明显的看出,更多的英语语料,对于其它语言输出的表现,都是促进的。同样,其它语言也能反过来促进英语输出的表现。 为什么是这样?因为英语是世界上“最全面”的语言。 这里的最全面,说的是,英语能够最全面的覆盖所有世界模型,知识体系,使用的最广,对其它知识的学习,正面作用最大。 而中文,从图中看,能够促进其它语言输出。但其它语言的语料,对中文输出,影响极度负面。
二、盲目多学不仅无益,反而有害
事实:在这个论文中,加入更多训练语言,会让每种语言的损失相对变差,这是论文所称的 curse of multilinguality。但它并非只能靠“给每种语言加同样多的数据”来解决。它是怎么解决的呢?但是首先要增加脑容量,把模型的size做大。通过这种方法呢,就相当于把上限提高了。第二呢就是多学可共享的东西。比如英语,就是各个语言都会共享的一个底层的基础,把英语的内容提高了,其他的语言都会受益。
洞见:对人类学习来说,同时学更多东西,必然面临性能退化的压力,表现在人脑呢也就是记不住或者记乱了,或者是东拉西扯。但退化不是线性的:如果新技能与旧技能存在可复用结构,你不需要按项目数线性增加每项投入,而更像是扩充脑容量 + 利用迁移抵消部分损失。
为什么:多任务共享同一套认知资源(注意力、工作记忆、抽象结构);当任务数增加,资源竞争带来退化。但若任务间共享结构足够多,学习会把一部分投入“摊销”到多个任务上,于是平均边际成本下降。
怎么用:
- 扩展知识面时,先找共享结构,也就是举一反三的部分:例如先补“通用底层”(数学、逻辑、写作结构、统计思维),再分叉到多个方向,比如物理、生物、脑科学、计算机等等。
- 别用“平均主义”分配时间:对相似簇可以减少重复练习,把时间挪给“边界更远、迁移更弱”的部分。对于那些不容易被这些通用知识覆盖的部分,可能就要多花时间去学习。坏处呢,就是时间成本增加。好处也很明显,你多花时间,别人也多花时间。
三、从头开始,还是站在巨人肩膀上?
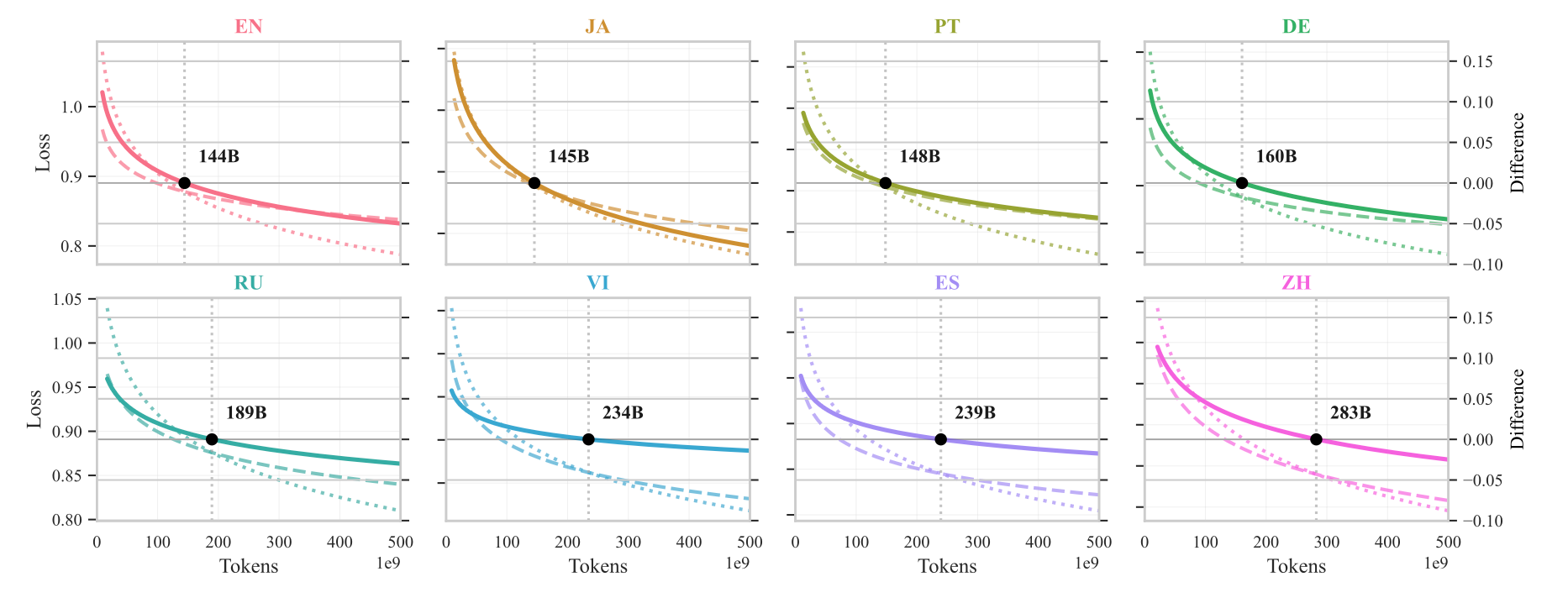
事实:当目标是优化某个语言,你有两个选择:你可以选择从通用多语言底座微调,或者是从头训练。两者在不同预算下,谁更划算,并不一样。从上面这张图可以看出来,小虚线是从头开始训练,大虚线是站在巨人的肩膀上,fine tune一个现有的模型。我们可以清晰的看到,在某个点上,小虚线的行动超过了大虚线,它更低了,就是它的偏差更少。什么意思呢?就是从这个点开始,重头训练就比finetuning一个现有的模型性能更好。只要你的数据比这个数字大,就一定会是这样。
洞见:人类学习里,“拿现成基础快速上手”(类比微调)适合短期目标;但若追求长期上限,往往需要某个阶段开始“回到第一性原理重建”(类比从头训练),否则会被早期借力形成的偏差与上限束缚住。
为什么?:微调之所以前期快,是因为它复用既有表征,减少冷启动;但它也继承既有表征的偏置与边界。长期来看,从头构建的体系能更贴合目标分布,最终超过“打补丁式”的适配。论文的曲线差异就是把这种“短期优势 vs 长期上限”量化出来。做一个类比呢,就是比如小公司且它的产品往往的这种一些开源模型在上面改或者开源代码在上面改,能很快做出产品,但时间长了,他就会发现把这些开源模型完全贴合它的业务逻辑,困难会越来越大。反而是那些自己公司手写出来的所谓的时战代码,贴合业务逻辑更准确、更高效。
怎么用:
- 先问自己预算与目标:若只为“尽快可用”,那就优先找能复用的底座,课程、模板、教练、成熟框架什么的;若为长期高强度,把某个阶段专门留给从头开始。
- 阶段化策略:先借力巨人肩膀,达成可用水平,再切换到系统化训练,两条腿走路,把隐含知识补齐。
四、智力才是决定性因素?
事实:跨语言迁移的差异在训练早期就出现并保持。训练更久,不能让模型性能显著提高。但更大的模型规模,能明显缓解负干扰,提高模型整体性能。
洞见:在人类学习中,早期的学习习惯与知识积累,会相互干扰;当你发现两个领域互相拖拽时,单纯再熬更久未必有效。反而应优先提升“脑容量”,比如外部脑,认知框架、工具,提高注意力质量,外部记忆系统等,让多套表征能并存在脑中,有效的提高了知识量。
为什么?:如果脑容量小,延长学习时间只是重复强化冲突表征,拖慢学习进度。而“脑容量提升”提供更多表示空间与更好的冲突分解能力(论文中对应:更大模型更能提升 interference 能力)。
怎么用:
- 早期不要把强干扰的两件事高频交替;先分别建立稳定表征,再做交叉迁移。
- 若必须并行,优先做“容量升级”:用更清晰的笔记体系、概念图、对比表,把冲突点显式化,而不是只追加学习时长。